How to Upload a Robotstxt File to Wix
You have more than control over the search engines than you think.
Information technology is truthful; you can dispense who crawls and indexes your site – even down to individual pages. To control this, you will demand to utilize a robots.txt file. Robots.txt is a uncomplicated text file that resides inside the root directory of your website. It informs the robots that are dispatched by search engines which pages to crawl and which to overlook.
While non exactly the be-all-and-terminate-all, you have probably figured out that it is quite a powerful tool and volition allow you to present your website to Google in a fashion that you desire them to see it. Search engines are harsh judges of character, so it is essential to make a great impression. Robots.txt, when utilized correctly, can better clamber frequency, which can impact your SEO efforts.
And then, how do you create one? How practise yous apply information technology? What things should you avoid? Check out this postal service to find the answers to all these questions.
What is A Robots.txt File?
Back when the internet was but a baby-faced kid with the potential to do neat things, developers devised a way to crawl and index fresh pages on the spider web. They called these 'robots' or 'spiders'.
Occasionally these lilliputian fellas would wander off onto websites that weren't intended to be crawled and indexed, such equally sites undergoing maintenance. The creator of the world's commencement search engine, Aliweb, recommended a solution – a route map of sorts, which each robot must follow.
This roadmap was finalized in June of 1994 by a collection of internet-savvy techies, as the " Robots Exclusion Protocol".
A robots.txt file is the execution of this protocol. The protocol delineates the guidelines that every accurate robot must follow, including Google bots. Some illegitimate robots, such equally malware, spyware, and the like, by definition, operate outside these rules.
You lot tin accept a peek backside the curtain of whatever website by typing in whatsoever URL and adding: /robots.txt at the end.
For instance, here'due south POD Digital's version:

Every bit you can see, it is not necessary to accept an all-singing, all-dancing file equally we are a relatively small website.
Where to Locate the Robots.txt File
Your robots.txt file volition be stored in the root directory of your site. To locate information technology, open your FTP cPanel, and y'all'll be able to detect the file in your public_html website directory.

There is nothing to these files so that they won't be hefty – probably simply a few hundred bytes, if that.
Once you open the file in your text editor, you will be greeted with something that looks a piddling similar this:

If you aren't able to find a file in your site's inner workings, then you will have to create your own.
How to Put Together a Robots.txt File
Robots.txt is a super bones text file, and so it is actually straightforward to create. All you volition demand is a elementary text editor similar Notepad. Open a canvas and salve the empty page every bit, 'robots.txt'.
Now login to your cPanel and locate the public_html folder to access the site's root directory. Once that is open up, elevate your file into it.
Finally, you must ensure that you take gear up the right permissions for the file. Basically, equally the owner, you volition demand to write, read and edit the file, simply no other parties should be allowed to do so.
The file should brandish a "0644" permission lawmaking.
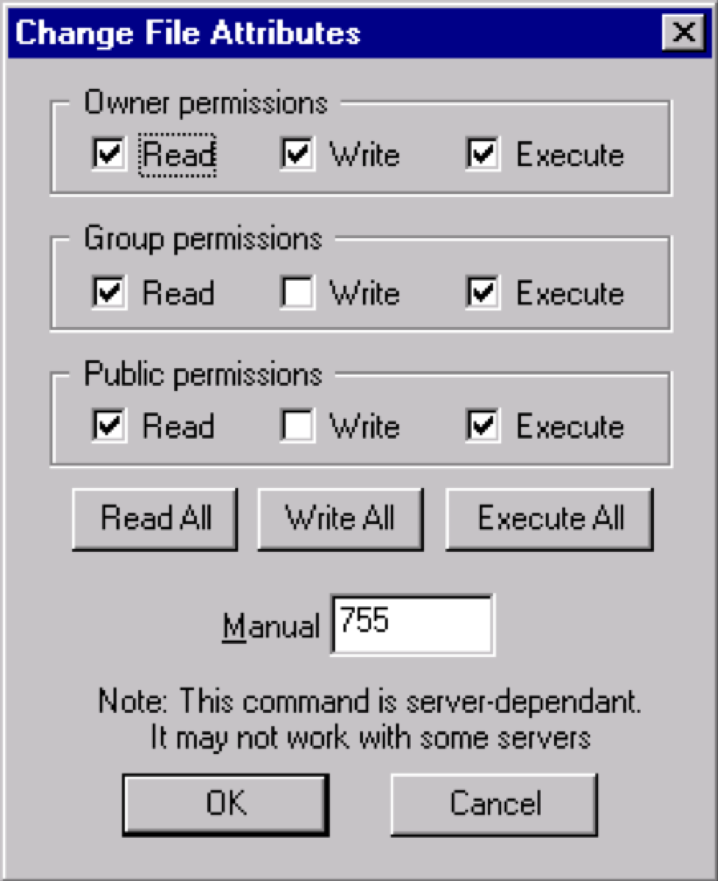
If non, you will need to modify this, so click on the file and select, "file permission".
Voila! You have a Robots.txt file.
Robots.txt Syntax
A robots.txt file is made up of multiple sections of 'directives', each beginning with a specified user-amanuensis. The user amanuensis is the proper noun of the specific clamber bot that the lawmaking is speaking to.
In that location are two options bachelor:
- You lot can utilize a wildcard to accost all search engines at once.
- You can accost specific search engines individually.
When a bot is deployed to clamber a website, it volition be drawn to the blocks that are calling to them.
Here is an example:

User-Agent Directive
The beginning few lines in each block are the 'user-amanuensis', which pinpoints a specific bot. The user-agent will friction match a specific bots name, so for case:

So if you want to tell a Googlebot what to do, for instance, offset with:
User-agent: Googlebot
Search engines e'er endeavour to pinpoint specific directives that relate most closely to them.
So, for instance, if you take got 2 directives, ane for Googlebot-Video and one for Bingbot. A bot that comes along with the user-amanuensis 'Bingbot' will follow the instructions. Whereas the 'Googlebot-Video' bot volition pass over this and go in search of a more specific directive.
Most search engines have a few different bots, hither is a list of the nearly common.
Host Directive
The host directive is supported only past Yandex at the moment, even though some speculations say Google does support it. This directive allows a user to decide whether to show the world wide web. earlier a URL using this cake:
Host: poddigital.co.britain
Since Yandex is the but confirmed supporter of the directive, information technology is not advisable to rely on it. Instead, 301 redirect the hostnames you don't want to the ones that y'all do.
Disallow Directive
We will cover this in a more than specific fashion a piddling after.
The second line in a block of directives is Disallow. You tin utilize this to specify which sections of the site shouldn't be accessed past bots. An empty disallow means it is a free-for-all, and the bots can delight themselves equally to where they practice and don't visit.
Sitemap Directive (XML Sitemaps)
Using the sitemap directive tells search engines where to discover your XML sitemap.
Notwithstanding, probably the most useful thing to practise would be to submit each ane to the search engines specific webmaster tools. This is because you can larn a lot of valuable information from each about your website.
However, if you are brusk on time, the sitemap directive is a viable alternative.
Crawl-Delay Directive
Yahoo, Bing, and Yandex tin can be a little trigger happy when it comes to itch, simply they do respond to the crawl-filibuster directive, which keeps them at bay for a while.
Applying this line to your block:
Crawl-delay: ten
ways that you tin can make the search engines wait ten seconds earlier crawling the site or 10 seconds before they re-access the site afterwards crawling – it is basically the aforementioned, simply slightly dissimilar depending on the search engine.
Why Use Robots.txt
At present that y'all know about the basics and how to use a few directives, you can put together your file. Nonetheless, this side by side footstep will come up downwardly to the kind of content on your site.
Robots.txt is non an essential chemical element to a successful website; in fact, your site tin can still function correctly and rank well without one.
Even so, there are several key benefits you must be enlightened of before you lot dismiss it:
-
Point Bots Abroad From Private Folders: Preventing bots from checking out your individual folders will make them much harder to detect and index.
-
Keep Resources Under Control: Each fourth dimension a bot crawls through your site, it sucks upward bandwidth and other server resources. For sites with tons of content and lots of pages, e-commerce sites, for instance, can take thousands of pages, and these resources tin be drained actually speedily. You can use robots.txt to brand information technology hard for bots to access individual scripts and images; this will retain valuable resources for real visitors.
-
Specify Location Of Your Sitemap: It is quite an of import betoken, you want to let crawlers know where your sitemap is located then they can scan it through.
-
Keep Duplicated Content Away From SERPs: By adding the rule to your robots, you lot tin can prevent crawlers from indexing pages which comprise the duplicated content.
You volition naturally want search engines to observe their fashion to the most important pages on your website. By politely cordoning off specific pages, you can control which pages are put in front of searchers (be sure to never completely cake search engines from seeing sure pages, though).

For instance, if nosotros look back at the POD Digital robots file, nosotros run across that this URL:
poddigital.co.great britain/wp-adminhas been disallowed.
Since that page is fabricated merely for the states to login into the control panel, it makes no sense to let bots to waste product their fourth dimension and energy itch it.
Noindex
In July 2019, Google appear that they would stop supporting the noindex directive besides equally many previously unsupported and unpublished rules that many of us have previously relied on.
Many of us decided to wait for alternative ways to use the noindex directive, and below you can see a few options y'all might decide to go for instead:
-
Noindex Tag/ Noindex HTTP Response Header: This tag can be implemented in 2 ways, starting time will exist every bit an HTTP response header with an X-Robots-Tag or create a <meta> tag which volition demand to be implemented within the <head> section.
Your <meta> tag should wait like the below example:<meta name="robots" content="noindex">
TIP: Bear in heed that if this folio has been blocked by robots.txt file, the crawler volition never see your noindex tag, and there is still a chance that this page will be presented within SERPs.
-
Countersign Protection: Google states that in most cases, if you hibernate a page backside a login, information technology should exist removed from Google's index. The only exception is presented if you utilise schema markup, which indicates that the folio is related to subscription or paywalled content.
-
404 & 410 HTTP Condition Code: 404 & 410 status codes correspond the pages that no longer be. Once a page with 404/410 condition is crawled and fully candy, it should be dropped automatically from Google's index.
Yous should clamber your website systematically to reduce the take chances of having 404 & 410 error pages and where needed employ 301 redirects to redirect traffic to an existing page.
-
Disallow rule in robots.txt: By adding a page specific disallow rule within your robots.txt file, you lot will forbid search engines from crawling the page. In most cases, your page and its content won't exist indexed. You should, notwithstanding, go along in listen that search engines are nonetheless able to index the page based on information and links from other pages.
-
Search Panel Remove URL Tool: This alternative root does not solve the indexing upshot in full, as Search Panel Remove URL Tool removes the folio from SERPs for a express time.
Yet, this might give y'all plenty fourth dimension to set up further robots rules and tags to remove pages in full from SERPs.
You tin can observe the Remove URL Tool on the left-paw side of the main navigation on Google Search Console.
Noindex vs. Disallow
So many of you lot probably wonder if it is ameliorate to use the noindex tag or the disallow dominion in your robots.txt file. We have already covered in the previous part why noindex rule is no longer supported in robots.txt and unlike alternatives.
If you lot desire to ensure that one of your pages is non indexed by search engines, you should definitely look at the noindex meta tag. It allows the bots to access the folio, but the tag will permit robots know that this page should not exist indexed and should not appear in the SERPs.
The disallow dominion might non be as constructive as noindex tag in general. Of course, by adding it to robots.txt, you are blocking the bots from itch your page, only if the mentioned page is linked with other pages by internal and external links, bots might withal alphabetize this page based on information provided by other pages/websites.
You should remember that if you disallow the page and add the noindex tag, then robots will never run into your noindex tag, which tin still cause the advent of the folio in the SERPs.
Using Regular Expressions & Wildcards
Ok, so now we know what robots.txt file is and how to utilize information technology, but y'all might think, "I take a big eCommerce website, and I would similar to disallow all the pages which contain question marks (?) in their URLs."
This is where nosotros would like to introduce your wildcards, which can be implemented within robots.txt. Currently, y'all take two types of wildcards to choose from.
-
* Wildcards - where * wildcard characters will match whatsoever sequence of characters you wish. This type of wildcard will be a swell solution for your URLs which follows the aforementioned blueprint. For case, you might wish to disallow from crawling all filter pages which include a question marker (?) in their URLs.

-
$ Wildcards - where $ will match the end of your URL. For example, if you want to ensure that your robots file is disallowing bots from accessing all PDF files, you might desire to add the dominion, like 1 presented beneath:

Let'due south quickly break downwards the example above. Your robots.txt allows any User-agent bots to crawl your website, but it disallows access to all pages which contain .pdf end.
Mistakes to Avoid
We accept talked a piffling bit about the things you could exercise and the different means you tin operate your robots.txt. Nosotros are going to delve a niggling deeper into each signal in this section and explain how each may plow into an SEO disaster if not utilized properly.
Do Not Block Practiced Content
It is important to non block whatsoever good content that you wish to present to publicity past robots.txt file or noindex tag. We have seen in the past many mistakes similar this, which have hurt the SEO results. You should thoroughly check your pages for noindex tags and disallow rules.
Overusing Crawl-Delay
We have already explained what the crawl-delay directive does, only you should avoid using it likewise oftentimes equally you are limiting the pages crawled past the bots. This may be perfect for some websites, but if you have got a huge website, you could be shooting yourself in the foot and preventing proficient rankings and solid traffic.
Case Sensitivity
The Robots.txt file is case sensitive, so you take to remember to create a robots file in the correct way. You should call robots file every bit 'robots.txt', all with lower cases. Otherwise, it won't work!
Using Robots.txt to Prevent Content Indexing
Nosotros take covered this a little bit already. Disallowing a page is the best way to try and prevent the bots crawling information technology directly.
But it won't work in the following circumstances:
-
If the page has been linked from an external source, the bots will even so menses through and index the folio.
-
Illegitimate bots will still clamber and index the content.
Using Robots.txt to Shield Individual Content

Some private content such as PDFs or thank you pages are indexable, fifty-fifty if you lot point the bots away from it. Ane of the best methods to become alongside the disallow directive is to identify all of your private content backside a login.
Of course, information technology does mean that it adds a farther step for your visitors, merely your content will remain secure.
Using Robots.txt to Hibernate Malicious Duplicate Content
Duplicate content is sometimes a necessary evil — think printer-friendly pages, for example.
However, Google and the other search engines are smart plenty to know when you are trying to hide something. In fact, doing this may actually draw more attention to information technology, and this is because Google recognizes the difference between a printer friendly page and someone trying to pull the wool over their eyes:

There is still a take chances it may be constitute anyway.
Here are three ways to bargain with this kind of content:
-
Rewrite the Content – Creating exciting and useful content will encourage the search engines to view your website as a trusted source. This suggestion is especially relevant if the content is a copy and paste job.
-
301 Redirect – 301 redirects inform search engines that a page has transferred to another location. Add a 301 to a page with duplicate content and divert visitors to the original content on the site.
-
Rel= "canonical – This is a tag that informs Google of the original location of duplicated content; this is especially of import for an e-commerce website where the CMS ofttimes generates duplicate versions of the aforementioned URL.
The Moment of Truth: Testing Out Your Robots.txt File
Now is the time to examination your file to ensure everything is working in the way you desire information technology to.
Google's Webmaster Tools has a robots.txt examination department, but it is currently simply available in the former version of Google Search Console. You lot will no longer be able to access the robot.txt tester by using an updated version of GSC (Google is working hard on adding new features to GSC, then perchance in the future, we will be able to see Robots.txt tester in the primary navigation).
Then start, yous volition need to visit Google Back up folio, which gives an overview of what Robots.txt tester can practice.
At that place yous volition likewise find the robots.txt Tester tool:
Choose the property you are going to piece of work on - for instance, your concern website from the dropdown list.
Remove anything currently in the box, supersede it with your new robots.txt file and click, test:

If the 'Exam' changes to 'Allowed', then you got yourself a fully functioning robots.txt.
Creating your robots.txt file correctly, means you lot are improving your SEO and the user experience of your visitors.
By allowing bots to spend their days crawling the right things, they will be able to organize and testify your content in the way you lot desire it to be seen in the SERPs.
How To Resource for CMS Platforms
- WordPress Robots.txt
- Magento Robots.txt
- Shopify Robots.txt
- Wix Robots.txt
- Joomla! Robots.txt
Source: https://www.semrush.com/blog/beginners-guide-robots-txt/
0 Response to "How to Upload a Robotstxt File to Wix"
Post a Comment